Data Movement Patterns
Version 1.0.0 Complete List of patterns & practices
In the early days of enterprise data, data processing was highly centralized. Everything existed in mainframes and data was primarily operational. A single copy of a database or file was shared by many applications. The functions that data processing supported were also clearly divided: online work during the day and offline (batch) work at night.
Gradually functions blurred. Informational data began to be extracted from the operational data to provide analysis and reporting. More systems were added, including smaller departmental systems. Although certain databases (usually still at the center) were still designated as the systems of record, applications were increasingly being installed on distributed systems, first on midrange computers and then on personal computers. These distributed systems collected new data and required access to the central data as well. This drove the need for providing the systems with their own copies of data to work on. This also began to open the Pandora's box of distributed data problems, especially as metadata and then knowledge data were introduced. It also raised the core question for multiple copies of data. Do you manage the data integrity through distributed updates from the applications, or update the local copy of data only and then manage the copy integrity through data movement services?
The concept of data warehousing recognized the need to stop proliferating the number of point-to-point informational data extracts and find a more manageable and reusable approach. This led to the definition of Extract, Transform, and Load (ETL) services, which has become industry-standard terminology for a certain class of data movement services.
Recently, Relational Database Management Systems (RDBMSs) have started to offer facilities that make it easy to replicate data. This is a valuable addition, but questions remain about how replication and ETL differ, and how both of these differ from the previous concept of creating an extract.
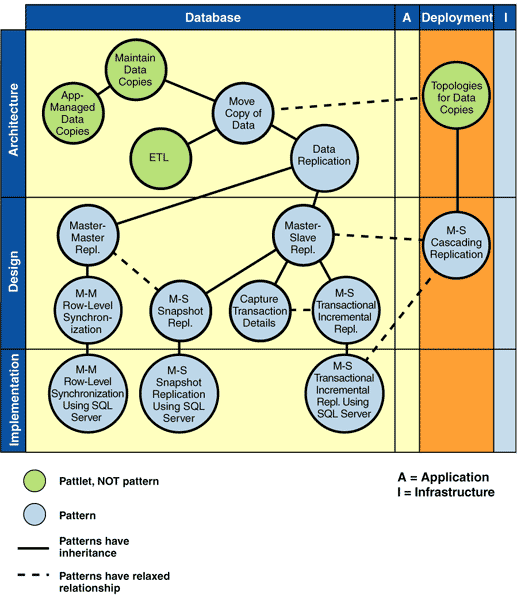
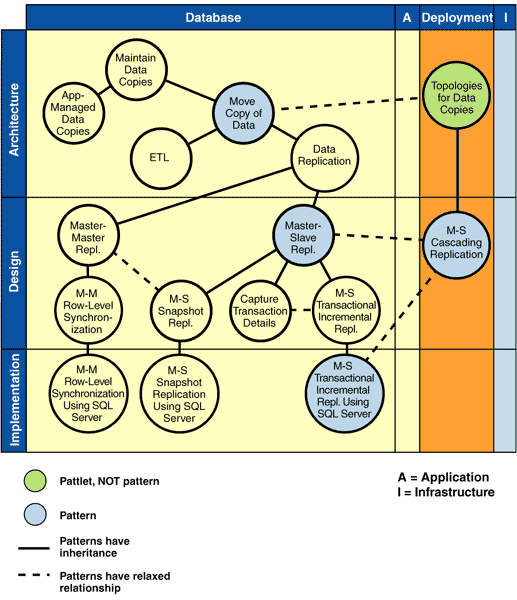
The result of this evolution is that the problem of moving data copies has become extremely complex. This set of data movement patterns addresses a subset of the problems involved with maintaining copies of data. The pattern graph in Figure 1 shows the full set of patterns currently provided. These patterns were selected based on workshops and reviews with customers, partners, and industry luminaries, who identified this set as being of critical importance now.
The patterns start at a high-level abstract architectural viewpoint. They then elaborate through increasing levels of detail, down to detailed design patterns. Both the architecture and design-level patterns are independent of the technology that you will choose to implement the patterns. Product considerations are introduced only at the implementation level. The implementation patterns provide best-practices guidance for implementing the designs indicated by using Microsoft SQL Server.
Figure 1 shows the data movement pattern cluster in the patterns frame.
Notice that four pattlets are named, as well as twelve patterns. A pattlet is a placeholder for a pattern that is believed to exist, but that has not yet been written. It is important to be clear that this is not a comprehensive set of pattlets. These are merely the pattlets that are key to establishing the context for the Data Movement patterns. Many more pattlets could have been named, for example Incremental Row-Level Replication. These pattlets are omitted to avoid overburdening Figure 1 and to focus on delivering high quality in the set of patterns that our guiding customers and partners identified as key.
Also notice that this view of the Pattern Frame uses two kinds of lines: solid and dotted. Each line indicates either an inheritance relationship, where a pattern inherits concepts from a previous one, or a more relaxed relationship, which indicates that one pattern can use another. For example, Master-Master Replicationcan use Master-Slave Snapshot Replicationfor its initial setup. And Master-Slave Replication can use Master-Slave Cascading Replication as a deployment design.
Architecture: Data Movement Root Patterns Figure 2 shows the root patterns of Data Movement cluster, which address the issue of how to maintain the overall integrity of a set of data copies. These patterns presume that you already have or are about to have more than one copy of the same data in more than one place. They also assume that when an application makes a change to the original data, you want that change to be reflected in some other place. You might want to have the changes reflected within the same application unit of work; or you might want them to be reflected after that unit of work completes. You might also want the changes reflected as soon as possible or according to some other schedule. Note: Making changes may include writing a copy of the change to an intermediary mechanism that the application recognises such as a user-created change log, or a messaging system. However, this is still within the application's local scope and changes will still be moved asynchronously.
The root pattlet, Maintain Data Copies, sets the context for the overall patterns cluster, which is that you want to create more than one copy of the same data. Your problem is how to serve the applications that will use all the copies and maintain the required state of integrity between the copies. The general solution is either to write synchronously to the copies from the originating transaction, or to post data synchronously to a local cache for later movement by an asynchronous service. The timeliness is given by the requirements of the applications.
The Application-Managed Data Copies pattlet shows that there is a cluster of patterns in the topic that are not yet addressed. These patterns would address the situation where the application ensures that copies of the data or derived data are updated during the same transaction which changed the original data.
The Move Copy of Data pattern is the root of the Data Movement patterns cluster. This architectural pattern is the root pattern for any type of asynchronous writing of copies of data. The pattern presents the fundamental data movement building block consisting of source, data movement link, and target. The data movement link consists of Acquire, Manipulate, and Write services. Transmissions in such a data movement building block are done asynchronously some time after the source is updated. Thus, the target applications must tolerate a certain amount of latency until changes are delivered. The rest of the Data Movement patterns follow from this pattern.
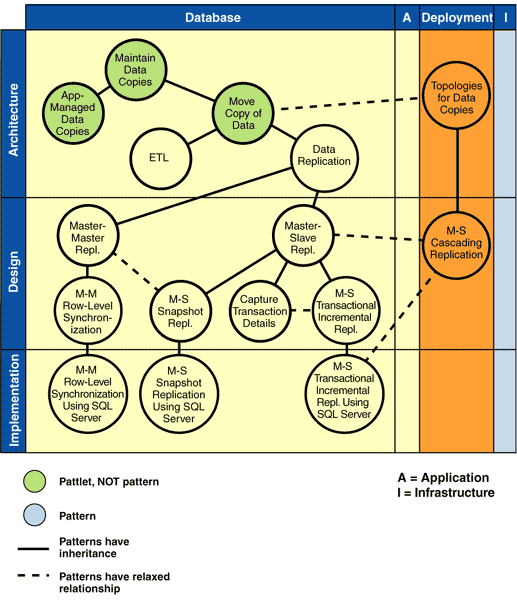
Architecture: Move Copy of Data Approaches The Move Copy of Data pattern just introduced identifies and distinguishes between two key architectural approaches to moving copies: ETL and Data Replication. Both of these approaches refine the architectural approach described in Move Copy of Data. The difference between them is in the complexity of the Acquire, Manipulate, and Write services described in the data movement building block. Figure 3 highlights the pattern and pattlet representing these two approaches to moving copies.
Data Replication applies the data movement building block to solve problems where the data copies involved are basically identical. The Acquire service gets the replication set from the source. Acquiring the data is straightforward and requires almost no manipulation before sending it on to the copies. The writing of the data (performed by the Write service) may also be simple, but if there are complexities they occur in the write stage. The complexities often arise due to the common data in the copies being updatable at any of the copies, and the consequent need to update conflicts across the copies.
ETL takes its name from the industry standard term Extract, Transform, and Load. This pattern applies when acquiring the data for copying is very complex due to the number and technical variety of the data stores involved. The Acquire service is therefore called Extract to distinguish it from the simple Acquire used in Data Replication. The pattern also applies when the data requires complex manipulation, such as aggregation, cleansing, and related-data lookup for enrichment, before it can be sent on to the copy. This complex form manipulation is called Transform to distinguish it from the simple Manipulate service described in Data Replication. Writing the data (called Load to distinguish it from the Write service described in Data Replication) is simple, because only one copy of the data is ever updatable, and typically the copies are simply overwritten with new data. ETL is commonly used to provision a data warehouse which has a radically different schema to the operational databases that provide it with data, and to clean up and clarify the data for users before it is put into the warehouse.
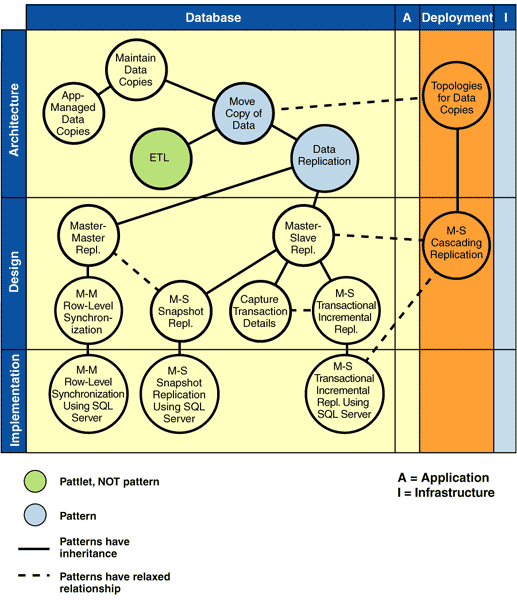
Design and Implementation: Data Replication Patterns The remainder of the Data Movement cluster focuses on refining Data Replication through various design and implementation patterns, which are highlighted in Figure 4.
The first key distinction, when refining Data Replication, is whether the replication is a master-master or master-slave type of replication.
The Master-Master Replication pattern describes the situation in which the same data can be updated in more than one copy (including the original); this creates the potential for different versions of the same data to exist. Any conflicts must be detected when the next replication occurs, and the conflicts have to be resolved according to some set of defined rules to maintain integrity. A common scenario here is when laptops work offline and make data changes, then need to synchronize the data changes with a shared server database which has been updated by other applications in the meantime. Note: Do not confuse the term master with the term prime. Master means that the copied data is updateable in that location, and that those changes must persist locally and must be replicated to some other copy. Prime means that this is the originating source of the data, which provides the system of record for the particular instance of the data. If you want to know the true state of the data, in a business sense, at any point in time, you go to the prime copy. It is possible for data to have the attributes of both prime and master; however, these terms describe different aspects of the data relationships.
The Master-Slave Replication pattern describes a one-way flow of data from the master to the slave copy or copies. In addition, the master data is seen as having priority over the other copies; that is, if any changes have been made to any of the slave copies since the last replication, these can be overwritten by the next replication from the master to the slaves. However, there are cases in which slave changes persist after a replication: for example when replication only adds to the slave data, rather than updating or replacing it.
An additional design pattern that takes context from Master-Master Replication is Master-Master Row-Level Synchronization. This pattern synchronizes a pair of master-master copies that have common data that is updatable at either copy. It describes how to detect and resolve conflicts at a row level. The second of the master copies must be created in a state that is consistent with the original master copy. You can use Master-Slave Snapshot Replication for this one-time need. This "can use" relationship is indicated by the dotted line in the Pattern Frame (see Figure 4). Master-Master Row-Level Synchronization Using SQL Servershows how to implement the Master-Master Row-Level Synchronization design pattern by using SQL Server.
The other design and implementation patterns take context from Master-Slave Replication. Master-Slave Snapshot Replicationis a pattern for creating a point-in-time copy of defined data. The copy consists of the entire set of data that is to be replicated, not just the changes since the last replication. The Capture Transaction Details pattern shows how to capture application changes made to the master data when either you do not have a DBMS-provided transaction log or you do not want to use that log for some reason. The result is a cache of data changes that can be used by Master-Slave Transactional Incremental Replication. This is a pattern for solving how to update copies by sending only the transactional data changes that have occurred in the master to the slave copies (rather than using the entire set of all row information). The pattern ensures that replicated data is available to applications only after dependent operations of the same transaction have been replicated.
As their names suggest, Implementing Master-Slave Snapshot Replication Using SQL Server and Implementing Master-Slave Transactional Incremental Replication Using SQL Server show SQL Server implementations of the respective design patterns.
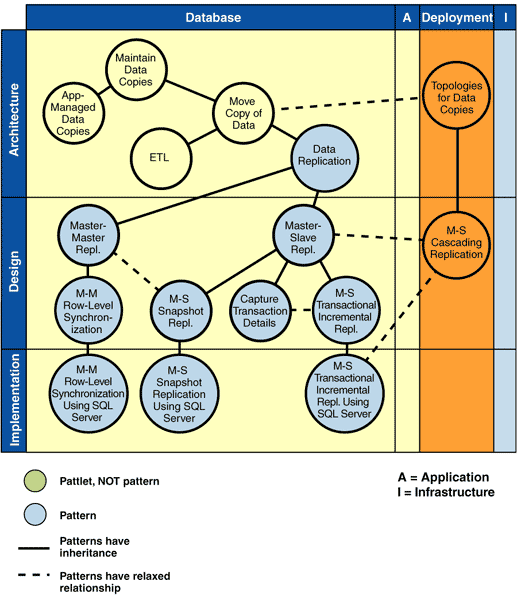
Data Replication Deployment The patterns highlighted in Figure 5 provide deployment guidance for Data Replication.
Currently, only a pattlet is provided at the architecture level. Topologies for Data Copies indicates that deploying a complex topology for moving redundant data involves a multistep use of the data movement building block described in Move Copy of Data.
The Master-Slave Cascading Replication pattern describes how to replicate data from one copy to many other copies, all of which require the same data. Figure 5 indicates that this deployment pattern is suitable for master-slave deployments only (not for master-master deployments). It also indicates that you can use Implementing Master-Slave Transactional Incremental Replication Using SQL Serverto implement the Master-Slave Cascading Replication pattern.
Data Movement Patterns The following table lists all of the patterns and pattlets identified in the Data Movement patterns cluster. Table 1: Data Movement Patterns Cluster
|