Capture Transaction Details
Version 1.0.0
GotDotNet community for collaboration on this
pattern
Complete List of patterns & practices
Context
You are about to design a replication link using
Master-Slave Transactional Incremental Replication. For
this purpose, you need access to transactional information on the
source, and a logging system will not fulfill this need for one of
the following reasons:
There is a logging system available at the source database but
for some good reasons you do not want to use it.
You do not have access to a logging system.
In these cases, you need to design the recording of transactions
on the source with your own artifacts.
Note: This pattern presumes knowledge of the concepts,
terms, and definitions of the
Data Replication architectural pattern, from which
this pattern inherits concepts and terms.
Problem
How do you design a recording of transactional information for
all changes to a source replication set?
Forces
Any of the following compelling forces justify using the
solution described in this pattern:
No access to transactional information. You cannot access
transactional information in the logging system because either you
are not using a database system at the source, or the database
system does not provide access to the transaction log.
Transactional information is not suitable. The
information provided might be usable in the originating database
only, for example, because it contains physical addresses instead of
key values and thus cannot be applied on the target.
The following enabling force facilitates the adoption of
the solution, and its absence might hinder such a move:
Recording for other purposes. Recording of transactions
is required for other purposes, for example, auditing.
Solution
The solution is to create additional database objects, such as
triggers and (shadow) tables, and to record changes of all tables
belonging to the replication set.
The details of the solution are separated into:
Prerequisites for recording transactional information
Designing your own recording of transactions
Note: This pattern uses the terms "transactions" and
"operations" with the following meanings:
A transaction is a collection of SQL commands that
form a unit of work. Depending on the relational database
management system (RDBMS), a transaction is started explicitly
by a command like Begin Transaction, or implicitly by the first
SQL command outside of a transaction. The transaction is ended
either explicitly by a commit or a rollback, or implicitly at
the end of every SQL command in autocommit mode.
An operation is the change (INSERT, UPDATE, or DELETE)
of an individual row within a transaction.
Prerequisites
This pattern depends on two features that the database management
system (DBMS) must provide, and on a prerequisite for the data
model:
Fine-grained clock. The order in which transactions are
executed on the source must be the same as the order in which they
are replayed on the target. Thus, the source clock must provide a
sufficiently fine resolution to preserve the order. A clock grain of
a millisecond is generally sufficient; many systems provide even
microseconds. A clock that only has a resolution of whole seconds
definitely prevents the use of this pattern.
Transaction Identifiers. The RDBMS must provide a means
to identify the operations that belong to the same transaction. This
is called a Transaction Identifier throughout the remaining
discussion. It is typically an opaque data type, and is generally
provided to handle distributed transactions.
Unique key. All tables of the replication set must have
either unique keys or another combination of columns that identifies
every row uniquely. The unique identifier of every row is referred
to as the Replication Key throughout this document.
Designing Your Own Recording of Transactions
Since you cannot access the logging system of the source to
acquire the transactional information, you have to implement the
recording of the transactions using other DBMS services, such as
triggers. Triggers are schema objects that perform additional
operations on behalf of an initial operation. Triggered operations
are also part of the initiating transaction and are logged in the
same way as any other operation.
Hint: It is also possible to record transactions by
changing the application to write a copy of the operation to a
user-defined database, but this is very unusual.
The triggered function has to collect the following information
for every committed transaction:
Transaction Identifier
Tables written to by the transaction
For every table, the rows that have been written must be
recorded. The data to be stored includes the current timestamp, the
type of operation (INSERT, UPDATE, or DELETE) and additional
information depending on the type of operation:
For INSERTs, the values of all fields must be recorded.
For UPDATEs that do not change the Replication Key, the new
values of all changed columns, including the column names, must
be recorded.
For UPDATEs that do change the Replication Key, the old and
new values of the Replication Key must also be saved.
Alternatively, you might record this as a DELETE of the old row
followed by an INSERT of the new row, unless this approach
violates integrity constraints.
For DELETEs, only the Replication Key of the deleted row is
needed. If the DELETE fires cascade deletes of related rows,
these additional deletes are recorded by further trigger
invocations on those rows.
Timestamp of when the transaction has been completed on the
source. If you cannot fire a trigger on the COMMIT, you can use the
timestamp of the last operation within the transaction instead.
To store the above information, you need a table for the
transactions and three additional shadow tables for each table that
belongs to the replication set. The shadow tables store the
inserted, updated, and deleted rows. The three shadow tables can be
combined into one by adding a column to store the type of operation;
depending on the type of operation, some of the columns will be
empty. Figure 1 shows the corresponding data model.
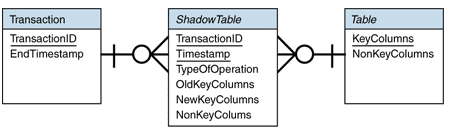
Figure 1: Data model to store transactional information
When an INSERT, UPDATE or DELETE is triggered, the following
steps must be taken:
Retrieve the Transaction Identifier of the current transaction.
UPDATE the current date and time in the EndTimestamp for the
current transaction in the Transaction table. If the UPDATE
statement returns no updated row, the transaction is new. Thus,
INSERT a new row with the Transaction Identifier and the current
date and time.
INSERT these values into the shadow table that corresponds to
the table being written:
Transaction Identifier
Current date and time
Type of operation (INSERT, UPDATE, or DELETE)
Operation values:
For an INSERT: the value of all columns For an UPDATE: the old and
new key values plus the values of the remaining columns For a
DELETE: the old key values
Transactions that are rolled back do not affect the source, and
consequently must not affect the target. For this reason, you do not
want to store information about rolled back transactions. The
recording of the transaction details should be done within the same
transaction that is being recorded. Then if the transaction is
rolled back, the recording of the transaction is rolled back as
well. Thus, information about rolled-back transactions is not
recorded.
Resulting Context
The use of this pattern has the following benefit and liability:
Benefit
Other useful services. Recording transactions is very
similar to other services, such as auditing. If the recorded
information is enriched with data, such as current user or role, it
can be the basis for auditing too.
Liability
Increasing space requirements. Recording transactions
writes new information into the transaction table and the shadow
tables. Thus, the space requirements of these tables are constantly
increasing. You should design and schedule a housekeeping process
that removes the transactional information from these tables once
they have been transmitted to the targets.
Next Considerations
The transactional information recorded by the use of this pattern
can be used by
Master-Slave Transactional Incremental Replication, which
is a separate pattern.
Variants
If you feel that the resolution of your clock is fine enough to
correctly order the transactions, but you do not trust the
resolution to order the operations within the transaction, you can
still use this pattern by following this variant. This variant also
increases the efficiency of replaying the transactions on the
target.
Combining Operations
The concept behind this variant is that the result of a
transaction does not depend on the order of its operations, but
rather upon the net effect on any particular row within the
transaction. So if an application on the source writes the same
record twice within a transaction, the operations on that row can be
aggregated to a single operation to be applied to the target. If the
source application writes more than twice to the same row in a
transaction, each of the other rows again aggregate with the
previous aggregation to create a new aggregated row.
The following table presents the aggregated operation that has to
be stored to achieve the correct net effect of two operations on the
same row identified by the replication key in a single transaction:
Table 1: Net Effects of Two Operations on the Same Row
| |
|
Second Operation |
|
|
| |
|
INSERT |
UPDATE |
DELETE |
| First Operation |
INSERT |
Impossible |
Insert |
Do nothing |
| |
UPDATE |
Impossible |
Update |
Delete |
| |
DELETE |
Update |
Impossible |
Impossible |
| |
|
|
|
|
The design of recording transactions on the source must now add
these steps when storing the operation:
Determine if there is an earlier operation on the same row
within the same transaction.
Determine the aggregated operation if an earlier operation is
found.
Store the recorded or combined operation.
When applying this variant you must not have any referential
integrity constraints on the target because the operations of the
transaction might be executed in a different order. This would
violate such constraints temporarily.
When combining several operations on the same row into a single
operation, updates of the Replication Key might become a problem.
However, because the target does not have referential integrity
constraints for the reason just given, an update of key values can
be converted into a delete of the old row, followed by an insert of
the new row.
Related Patterns
For more information, see the following related patterns:
Patterns That May Have Led You Here
Move Copy of Data. This pattern is the root
pattern of this cluster. It presents the fundamental data movement
building block consisting of source, data movement set, data
movement link, and target. Transmissions in such a data movement
building block are done asynchronously some time after the update of
the source. Thus, the target applications must tolerate a certain
amount of latency until changes are delivered.
Data Replication. This pattern presents the
architecture of a replication, which is a specific type of data copy
movement.
Master-Slave Replication. This pattern presents
the high-level design for a replication where changes at the source
are transmitted to the target by overwriting potential updates of
the target.
Patterns That You Can Use Next
Master-Slave Transactional Incremental Replication. This
pattern uses transactions to transmit changes from the source to the
target. These changes might have been recorded using the Capture
Transaction Details pattern.

|