![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Version 1.0.0
GotDotNet community for collaboration on this pattern
Complete List of patterns & practices
Context
You have decided to follow the Move Copy of Data pattern. Furthermore:
· You want to move data between two identical or very nearly identical data stores.
· You may have to allow the data involved to be updated by applications at either the source or the target, and if so you must manage the integrity of those changes.
Note: For simplicity, this pattern describes replicating between relational databases. The concepts, however, apply to other types of data stores as well.
Problem
What proven architectural approach should you follow to create nearly-identical copies of the data and to manage the integrity of the copies if they can be updated at both the source and target within a replication interval?
Forces
Most of the forces that were described in the Move Copy of Data pattern apply in this context and there are no additional ones. The relevant forces are repeated here for convenience.
Any of the following compelling forces would justify using the solution described in this pattern:
· Data availability no longer matches requirements. For example, your existing centralized data stores were designed to support regular business hours of 08:00 to 18:00, and these data stores must be taken offline for after-hours maintenance and reporting. Your other applications, however, must support customer-direct self-service, which requires 24-hour availability. Another example is you are writing applications that are going to be installed on laptops for a mobile field force that require the data to be available while working offline. This requires copying the data to the laptops and synchronizing changes later when the laptops reconnect to the network.
· Network or application platform is unreliable. For example, your network fails frequently or is shut down for significant periods of time so that your new applications cannot deliver the required levels of service.
· Network bandwidth does not support real-time data access performance requirements. In this case, you might need to avoid the real-time problem by making a local data copy available.
Hint: This force can lead to disaster if you misjudge it. Your early requirements, benchmarks, or prototyping might lead you to believe that the bandwidth is acceptable. However, a new or rapidly growing application can degrade performance quickly. The redundant data approach can minimize the effects of these changes. This approach carries its own risk, though, if the volume of data to be copied increases significantly, if latency requirements change, or if network bandwidth drops at the time you need to copy the data.
The following enabling forces facilitate the move to the solution, and their absence may hinder such a move:
· Latency tolerance. The other applications must be able to tolerate the wait that is associated with moving the data.
· Data changes are generally non-conflicting. Often the business use of the data makes it relatively easy to isolate changes to the original data and its copies. For example, if you are providing a new application on a laptop for a client manager to use when making customer calls, the manager may update client data during the call. It is highly unlikely that the customer will call the company and request changes to an existing copy of the data during the same time period.
Solution
Build on the data movement building block as described in Move Copy of Data by adding refinements that are appropriate to replication. To focus the terminology, the base building block for this pattern is called a replication building block. Also, in the special circumstances of the Master-Master Replication pattern, the building block will have a pair of related replication links to handle the two-way nature of the replication.
For the same reason, the data movement link is called replication link; the replication link transmits a replication set across the link. In the link, the Acquire and Write services are always simple, and the Write service may be simple (as in the Master-Slave Replication pattern) or complex (as in the Master-Master Replication pattern).
Figure 1 illustrates a replication building block.
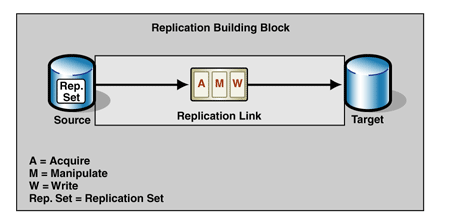
Figure 1: Replication building block
The following paragraphs describe the elements of the replication building block in comparison to the more generic elements of the data movement building block.
Source
In a replication building block, the source is generally a database that contains data to be replicated. One database can be the source for many replication building blocks. The source database can also serve as the target for another replication building block. For example, in the Master-Master Replication pattern, the same pair of data stores swap roles (source becomes target, and target becomes source) for a common movement set that is updateable in either data store.
Replication Set
A replication set is an identified set of data that exists within a single source, and it corresponds to the movement set. It is the subset of the particular database that you want to acquire for replication. For example, if you want to replicate data to a laptop for salespersons to use in making daily calls, each person needs a replication set containing the details of the clients that they are going to call on that day.
A replication set is made up of a group of replication units. A replication unit is the smallest amount of data that can be identified in a transmission. The replication unit can be any one of the following:
· The complete replication set
· A table of the replication set
· A transaction
· A row (from a table of the replication set)
· A column (from a row of a table of the replication set)
Replication Link
The replication link corresponds to the data movement link with specific refinements for replication.
A replication link is a connection between the source and target along which the relevant data is replicated from one database to another with appropriate security. Movement of a replication set across the link is called a transmission.
The replication link includes:
· The method of transmission of data at each step that moves data (which includes any intermediary transient data stores). For example, the method of transmission may be shared data storage, FTP, or a secure electronic link with managed row transmission.
· The Acquire, Manipulate, and Write replication services.
Acquire
The Acquire service gets the replication set from the source. Acquisition may be a simple one-step process, or it may be a multi-step process, for example if the replication set is in several tables in the data store, which could be a multistep process to acquire a composite movement set.
Hint: The Data Replication pattern works when you are dealing with composite movement sets for a single platform, but when multiple database management systems (DBMSs) and/or operating systems are involved, you probably need to use the Extract-Transform-Load (ETL) pattern.
Acquire can enrich the data by adding details, such as the time the data was acquired, to allow for management of the overall data integrity.
Acquire can obtain the replication sets from the database rows directly, or it can acquire them from data caches where only data changes are stored. Typically these are either DBMS log record stores or user-written caching databases. In this case, these stores should be considered the sources.
When acquiring data from these stores, Acquire must either collect all transactional changes or collect the net change, which is the final result of all the changes that have occurred to this row since the last transmission.
Hint: When you want to acquire a composite movement set, and you need to decide whether to follow the pattern and have a replication building block for each source, or to write a variant of Acquire that gets the whole set. This is the classic reusable modular code versus monolithic code question. Both approaches are valid in certain circumstances. In general, you can:
1. Use the multiple replication building block approach as your default. It is the most flexible and reusable, but you must evaluate whether it is efficient enough.
2. Use a composite movement set when the target set has a simple aggregated view of the source data. For example, you want to assemble a single view of customer data, and to do that you need extra customer data from many product databases. In the banking industry, this view could show that this customer has a current account, a savings account, and two mortgages. In the target, this is held in a single aggregated record. In the source, these are all held in separate Product databases on the same platform. There is a common identifier for Customer in all the databases. Acquire then fetches the customer details from each database, and Manipulate stitches them together for Write to write to the target. (If the situation is any more complex than this, though, you are getting into ETL).
Manipulate
The Manipulate service changes the form of the data in a simple way and passes it on in a format that can easily be written to the target.
The essence of replication is that manipulation is simple and can be performed either within the database language (SQL) or by a simple tool provided usually by the DBMS vendor. Manipulate should not contain complex logic of the sort that would require you to write applications to implement it. The simplest manipulation is a mapping to the target structure by using the tool or SQL. This may include semantic changes such as mapping to a date data type. Other valid manipulations are:
· Splitting or combining data elements or rows
· Code page translations
· Elementary data integrity checks, such as type validation
· Aggregation functions that can be performed simply within the technology
Note: The Manipulate service differs from the Transform service of ETL in the complexity of the change it performs. Although this difference can be difficult to characterize precisely, the goal is to differentiate Data Replication from ETL, which is another pattern.
Write
The Write service writes the data that the Manipulate service prepared to the target. If the target has changed the replication data since the last replication transmission, the Write service must check its rules to see whether it must resolve conflicts or not.
If it does not have to resolve the conflicts, then it has to decide whether to:
· Overwrite the target with the new transmission data.
· Append the new transmission data, in which case Write must handle row versioning.
If it does have to resolve the conflicts, the Master-Master Replication pattern applies for conflict detection and resolution.
Target
In a replication building block, the target is the database where the data is written. The structure of the target is very similar or identical to the source. The target could be several databases.
If the data that you replicate to the target can be updated by applications there, and if the changes need to be reflected back into the source, you should have a second replication link returning so that the roles of source and target are exchanged. This relationship must be explicit because of the data integrity issues; it is a replication link attribute and is described in the Master-Master Replication and Master-Master Row-Level Synchronization patterns.
Examples
The following examples illustrate how to use the replication building block.
Feeding Management Information Reports
You need to build a new system that provides online transaction processing (OLTP) transactions and summarized management information reports based on the information of the previous day. The summary reports are not updatable; they are management reports and are not used for what-if analysis. There are many reports that constitute a significant workload. You do not want the platform that hosts the operational database to bear the additional load of the reporting, and the additional complexity of accessing the previous day's data.
The solution is to implement a master-slave replication link between the operational source database and a reporting target database. For more information, see the Master-Slave Replication, Master-Slave Snapshot Replicationand Master-Slave Transactional Incremental Replicationdesign patterns.
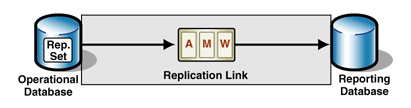
Figure 2: Replication from an operational database to a reporting database
Provisioning a Mobile Sales Force and Synchronizing Their Work
Sales forces must have product and customer information available during their visits. They want to update customer information such as addresses immediately.
The solution is to implement a master-master replication link between the central customer source database and the sales force laptop target databases. For more information, see the Master-Master Replication and Master-Master Row-Level Synchronization patterns.
In a master-master replication, any changes that the target makes to the replicated data are sent back to the source, so that the source can stay synchronized with the target. Figure 3 illustrates this type of replication.
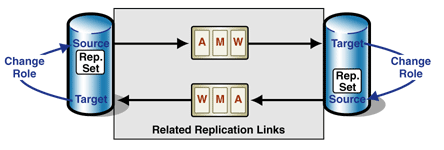
Figure 3: Master-master replication
Every sales representative gets an extract of an operational source database on his or her laptop. This target database can be updated while the laptop is disconnected from the master database. The next time the laptop is connected to the central database, any changes to the laptop target customer data are sent to the operational source database.
Provisioning a Large Number of Targets
Airline companies need a high volume of data for the computation of optimal flight routes for every individual flight. The data consists of weather information, fuel prices, flight rights on territories, and other restrictions. The data is only partially accessible in a machine-readable manner. One airline offers the service of maintaining this data in a database and provides the data to customers as a product. The customers can update the received data, but these updates are not sent back.
The solution is to implement the Master-Slave Cascading Replication pattern to provide the data to a large number of targets. For more information, see the Master-Slave Replication and Master-Slave Cascading Replication patterns.
The airline uses a central source database for data maintenance. From there, the data is replicated to an intermediary target database, which in turn serves as the source for replication to the customer sites. The replication is invoked immediately after every transaction.
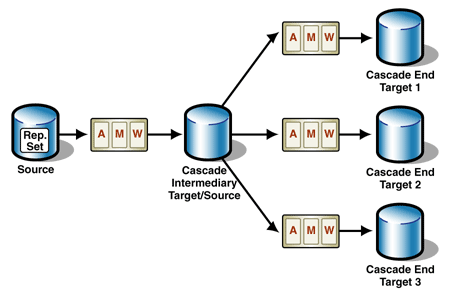
Figure 4: Cascading replication
Resulting Context
This pattern results in the same benefits and liabilities described in the Move Copy of Data pattern:
Benefits
· Target data store optimization. The Target data stores can be configured and optimized in different ways to best support their different types of data access. For example, one case might be about manipulating individual rows, while another might be about reports on many records.
· Data autonomy. When the data stores are relatively independent of each other and can have different owners, the content of the source data store can be provided as a product, and it is then the responsibility of the target owner to operate on its data.
· Data privacy. By restricting the movement set to an agreed subset of the source data store, Move Copy of Data can provide only data that the application (or users) at the target can see.
· Security. Source data stores are not accessed by the target applications and hence are more secure.
Liabilities
· Administration complexity. This pattern might introduce additional operational tasks for data store administrators. For example, the ongoing transmissions have to be checked to ensure that they are running smoothly. Also, administrators must monitor the impact of the involved resources, such as the growth of cached changes, log files, and so on.
· Potential increased overhead on the sources. Every acquisition of data loads a certain overhead on the source. It is important to properly plan the additional load caused by extracting snapshots or by logging transactions that will be replicated. The additional load has to be compared to the load that would occur if all applications were connected to a single data store. You can use this pattern to optimize the operational load.
· Potential security exposure. The target data stores must not allow access to source data that the source would not permit. This is another administration challenge.
Next Considerations
Use the pattern to build your own solution by following this simple process:
1.Analyze the other application's data requirements to identify the existing source databases that the solution will use.
2.Within these source databases, identify the actual data required by the other applications and map this set of tables/columns to the target.
3.Define the operational requirements for the target and match these requirements to the source capabilities to deliver the data.
4.Define the functional requirements on Acquire, Manipulate, and Write (AMW) for each replication building block, and hence design the end-to-end AMW process.
5.Determine how many replication building blocks your architecture will require by considering the overall topology that is required to deliver the operational requirements for both source and target. Hence, divide the AMW functions amongst these building blocks.
6.Define the replication links between databases, their attributes, and their relationships and hence plan the full replication deployment that meets the combined functional and operational requirements.
7.Understand the operational considerations for each of replication link, match them to the overall replication operational requirements, and thus create the schedule for each replication link.
To apply this process, you must consider the following design issues:
· Replication set size. Decide whether to replicate an entire table, a subset of a table, or data from more than one table. This is a tradeoff among the amount of data that changes, the overall table size, and the complexity of the link.
· Transmission volume. Choose the right amount of data to transmit. The decision between sending all changes for any one row, or just the net effect of all the changes, is a key one.
· Replication set data changes at the target. If these have to occur and if the source wants to see the changes, then try to make the changes naturally non-conflicting to avoid the need for conflict detection and resolution.
· Replication frequency. Decide the appropriate timing of the replication for the requirements and optimize the use of computing resources.
· Replication unit. As defined earlier, a replication set consists of a group of replication units. Identify the unit of data that will be transmitted from the source to the target. In the extreme requirements, this will be a transaction as it has been executed on the source. A less precise but easier to achieve requirement is to move a changed row. For environments with a high risk of conflicts, it can also be an individual change in a cell within a record.
· Initiator. Decide whether the source pushes the data or the target pulls it, and make sure that throughout your replication topology these decisions do not cause later replication links to have problems meeting their operational requirements.
· Locking issues. Verify that you can accept the locking impact of the replication on the source. If not, verify that a slight decrease in consistency at a point in time is acceptable for the targets so you can avoid lock conflict.
· Replication topology. Identify the players, their roles, and the overall integrity.
· Security. Ensure that the replicated data is treated with the right level of security at the target given the source security conditions. Also, verify that your replication link is secure enough in the overall topology requirements.
· Key updates. Verify whether the source allows updates to the key of records belonging to the replication set. If so, special care must be taken for a consistent replication of such operations.
Note:Key updates are SQL updates to the columns of the physical key within a replication set. Such key updates must be handled specially by the replication.
· Referential integrity. Verify whether the target has implemented referential integrity. If so, you need rules to prevent changes from the replication link being applied twice if the change triggers a target change in another replicated table.
Related Patterns
For more information, see the following related patterns:
Patterns That May Have Led You Here
· Move Copy of Data. The Move Copy of Data pattern describes the fundamental architecture building block from which Data Replication inherits basic concepts.
Patterns That You Can Use Next
· Master-Master Replication. This pattern discusses a situation in which changes occur to a common set of data at either source or target, and the other party wants such changes replicated to it.
· Master-Slave Replication. This pattern presents the solution for a replication where the changes are replicated to the target without taking changes of the target into account. It will eventually overwrite any changes on the target.
Other Patterns of Interest
· Master-Slave Cascading Replication. This pattern discusses a replication deployment where many targets want to subscribe to the replication set that is being replicated
· Extract-Transform-Load (ETL). This pattern is an alternative to Data Replication, if the Acquire or the Manipulate service is complex, but the Write service is simple.